Un modèle peut créer une solution de raccourci et apprendre à identifier des images de vaches en se concentrant sur l’herbe verte qui apparaît sur les photos, plutôt que sur les formes et les motifs plus complexes des vaches. Crédit : Jose-Luis Olivares, MIT, avec photo d’iStockphoto
Une nouvelle méthode oblige un modèle d’apprentissage automatique à se concentrer sur plus de données lors de l’apprentissage d’une tâche, ce qui conduit à des prédictions plus fiables.
Si votre chauffeur Uber prend un raccourci, vous arriverez peut-être plus rapidement à destination. Mais si un modèle d’apprentissage automatique prend un raccourci, il peut échouer de manière inattendue.
En apprentissage automatique, une solution de raccourci se produit lorsque le modèle s’appuie sur une simple caractéristique d’un ensemble de données pour prendre une décision, plutôt que d’apprendre la véritable essence des données, ce qui peut conduire à des prédictions inexactes. Par exemple, un modèle peut apprendre à identifier des images de vaches en se concentrant sur l’herbe verte qui apparaît sur les photos, plutôt que sur les formes et les motifs plus complexes des vaches.
Une nouvelle étude menée par des chercheurs de AVEC explore le problème des raccourcis dans une méthode d’apprentissage automatique populaire et propose une solution qui peut empêcher les raccourcis en forçant le modèle à utiliser plus de données dans sa prise de décision.
En supprimant les caractéristiques les plus simples sur lesquelles le modèle se concentre, les chercheurs l’obligent à se concentrer sur les caractéristiques plus complexes des données qu’il n’avait pas prises en compte. Ensuite, en demandant au modèle de résoudre la même tâche de deux manières – une fois en utilisant ces fonctionnalités plus simples, puis en utilisant également les fonctionnalités complexes qu’il a maintenant appris à identifier – ils réduisent la tendance aux solutions de raccourci et améliorent les performances du modèle.
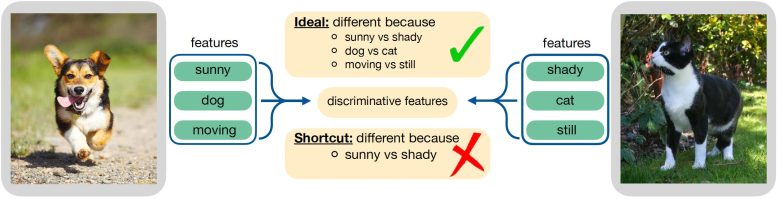
Les chercheurs du MIT ont développé une technique qui réduit la tendance des modèles d’apprentissage contrastifs à utiliser des raccourcis, en forçant le modèle à se concentrer sur des caractéristiques des données qu’il n’avait pas prises en compte auparavant. Crédit : Avec l’aimable autorisation des chercheurs
Une application potentielle de ce travail est d’améliorer l’efficacité des modèles d’apprentissage automatique qui sont utilisés pour identifier les maladies dans les images médicales. Les solutions de raccourci dans ce contexte pourraient conduire à de faux diagnostics et avoir des implications dangereuses pour les patients.
« Il est encore difficile de dire pourquoi les réseaux profonds prennent les décisions qu’ils prennent, et en particulier, sur quelles parties des données ces réseaux choisissent de se concentrer lorsqu’ils prennent une décision. Si nous pouvons comprendre plus en détail comment fonctionnent les raccourcis, nous pouvons aller encore plus loin pour répondre à certaines des questions fondamentales mais très pratiques qui sont vraiment importantes pour les personnes qui essaient de déployer ces réseaux », explique Joshua Robinson, doctorant au Laboratoire d’informatique et d’intelligence artificielle (CSAIL) et auteur principal de l’article.
Robinson a écrit l’article avec ses conseillers, l’auteur principal Suvrit Sra, le professeur agrégé de développement de carrière Esther et Harold E. Edgerton au Département de génie électrique et d’informatique (EECS) et un membre principal de l’Institute for Data, Systems, and Society (IDSS) et le Laboratoire des Systèmes d’Information et de Décision ; et Stefanie Jegelka, professeure agrégée en développement de carrière du X-Consortium à l’EECS et membre du CSAIL et de l’IDSS; ainsi que le professeur adjoint de l’Université de Pittsburgh Kayhan Batmanghelich et les doctorants Li Sun et Ke Yu. La recherche sera présentée à la Conférence sur les systèmes de traitement de l’information neuronale en décembre.
Le long chemin pour comprendre les raccourcis
Les chercheurs ont concentré leur étude sur l’apprentissage contrastif, qui est une forme puissante d’apprentissage automatique auto-supervisé. Dans l’apprentissage automatique auto-supervisé, un modèle est entraîné à l’aide de données brutes qui n’ont pas de descriptions d’étiquettes provenant d’humains. Il peut donc être utilisé avec succès pour une plus grande variété de données.
Un modèle d’apprentissage auto-supervisé apprend des représentations utiles de données, qui sont utilisées comme entrées pour différentes tâches, comme la classification d’images. Mais si le modèle prend des raccourcis et ne parvient pas à capturer des informations importantes, ces tâches ne pourront pas non plus utiliser ces informations.
Par exemple, si un modèle d’apprentissage auto-supervisé est formé pour classer la pneumonie dans les rayons X d’un certain nombre d’hôpitaux, mais qu’il apprend à faire des prédictions basées sur une étiquette qui identifie l’hôpital d’où provient l’analyse (parce que certains hôpitaux ont plus de pneumonie cas que d’autres), le modèle ne fonctionnera pas bien lorsqu’il reçoit des données d’un nouvel hôpital.
Pour les modèles d’apprentissage contrastifs, un algorithme d’encodeur est entraîné pour discriminer entre des paires d’entrées similaires et des paires d’entrées dissemblables. Ce processus code des données riches et complexes, comme des images, d’une manière que le modèle d’apprentissage contrastif peut interpréter.
Les chercheurs ont testé des encodeurs d’apprentissage contrastifs avec une série d’images et ont découvert qu’au cours de cette procédure de formation, ils étaient également la proie de solutions de raccourci. Les encodeurs ont tendance à se concentrer sur les caractéristiques les plus simples d’une image pour décider quelles paires d’entrées sont similaires et lesquelles sont différentes. Idéalement, l’encodeur devrait se concentrer sur toutes les caractéristiques utiles des données lors de la prise de décision, explique Jegelka.
Ainsi, l’équipe a rendu plus difficile de faire la différence entre les paires similaires et dissemblables, et a constaté que cela change les fonctionnalités que l’encodeur examinera pour prendre une décision.
« Si vous compliquez de plus en plus la tâche de faire la distinction entre des éléments similaires et dissemblables, votre système est alors obligé d’apprendre des informations plus significatives dans les données, car sans apprendre cela, il ne peut pas résoudre la tâche », dit-elle.
Mais l’augmentation de cette difficulté a entraîné un compromis : l’encodeur s’est mieux concentré sur certaines caractéristiques des données, mais s’est aggravé pour se concentrer sur d’autres. Il semblait presque oublier les caractéristiques les plus simples, dit Robinson.
Pour éviter ce compromis, les chercheurs ont demandé à l’encodeur de faire la distinction entre les paires de la même manière qu’il l’avait fait à l’origine, en utilisant les fonctionnalités les plus simples, et également après avoir supprimé les informations qu’il avait déjà apprises. Résoudre la tâche dans les deux sens simultanément a permis d’améliorer l’encodeur dans toutes les fonctionnalités.
Leur méthode, appelée modification de caractéristiques implicites, modifie de manière adaptative les échantillons pour supprimer les caractéristiques les plus simples que l’encodeur utilise pour discriminer les paires. La technique ne repose pas sur l’intervention humaine, ce qui est important car les ensembles de données du monde réel peuvent avoir des centaines de caractéristiques différentes qui pourraient se combiner de manière complexe, explique Sra.
Des voitures à la MPOC
Les chercheurs ont effectué un test de cette méthode en utilisant des images de véhicules. Ils ont utilisé une modification implicite des caractéristiques pour ajuster la couleur, l’orientation et le type de véhicule afin de rendre plus difficile pour l’encodeur de faire la distinction entre des paires d’images similaires et différentes. L’encodeur a amélioré son précision sur les trois caractéristiques – texture, forme et couleur – simultanément.
Pour voir si la méthode résisterait à des données plus complexes, les chercheurs l’ont également testée avec des échantillons d’une base de données d’images médicales de la maladie pulmonaire obstructive chronique (MPOC). Encore une fois, la méthode a conduit à des améliorations simultanées de toutes les fonctionnalités évaluées.
Bien que ce travail fasse des progrès importants dans la compréhension des causes des solutions de raccourci et dans leur résolution, les chercheurs affirment que continuer à affiner ces méthodes et les appliquer à d’autres types d’apprentissage auto-supervisé sera la clé des progrès futurs.
« Cela est lié à certaines des plus grandes questions sur les systèmes d’apprentissage en profondeur, comme « Pourquoi échouent-ils ? » » et « Pouvons-nous connaître à l’avance les situations où votre modèle échouera ? Il reste encore beaucoup à faire si vous voulez comprendre l’apprentissage raccourci dans toute sa généralité », déclare Robinson.
Référence : « L’apprentissage contrastif peut-il éviter les solutions de raccourci ? » par Joshua Robinson, Li Sun, Ke Yu, Kayhan Batmanghelich, Stefanie Jegelka et Suvrit Sra, 21 juin 2021, Informatique > Apprentissage automatique.
arXiv:2106.11230
Cette recherche est soutenue par la National Science Foundation, les National Institutes of Health et le programme SAP SE Commonwealth Universal Research Enhancement (CURE) du ministère de la Santé de Pennsylvanie.