Les neuroscientifiques du MIT ont développé un modèle informatique capable de localiser les sons. Crédit : Jose-Luis Olivares, MIT
MIT neuroscientists have developed a computer model that can answer that question as well as the human brain.
The human brain is finely tuned not only to recognize particular sounds, but also to determine which direction they came from. By comparing differences in sounds that reach the right and left ear, the brain can estimate the location of a barking dog, wailing fire engine, or approaching car.
MIT neuroscientists have now developed a computer model that can also perform that complex task. The model, which consists of several convolutional neural networks, not only performs the task as well as humans do, it also struggles in the same ways that humans do.
“We now have a model that can actually localize sounds in the real world,” says Josh McDermott, an associate professor of brain and cognitive sciences and a member of MIT’s McGovern Institute for Brain Research. “And when we treated the model like a human experimental participant and simulated this large set of experiments that people had tested humans on in the past, what we found over and over again is it the model recapitulates the results that you see in humans.”
Findings from the new study also suggest that humans’ ability to perceive location is adapted to the specific challenges of our environment, says McDermott, who is also a member of MIT’s Center for Brains, Minds, and Machines.
McDermott is the senior author of the paper, which was published on January 27, 2022, in Nature Human Behavior. The paper’s lead author is MIT graduate student Andrew Francl.
Modélisation de la localisation
Lorsque nous entendons un son tel que le sifflet d’un train, les ondes sonores atteignent nos oreilles droite et gauche à des moments et à des intensités légèrement différents, selon la direction d’où provient le son. Certaines parties du mésencéphale sont spécialisées dans la comparaison de ces légères différences pour aider à estimer la direction d’où provient le son, une tâche également connue sous le nom de localisation.
Cette tâche devient nettement plus difficile dans les conditions du monde réel, où l’environnement produit des échos et où de nombreux sons sont entendus en même temps.
Les scientifiques cherchent depuis longtemps à construire des modèles informatiques capables d’effectuer le même type de calculs que ceux utilisés par le cerveau pour localiser les sons. Ces modèles fonctionnent parfois bien dans des environnements idéalisés, sans bruit de fond, mais jamais dans des environnements réels, avec leurs bruits et leurs échos.
Pour développer un modèle plus sophistiqué de localisation, l’équipe du MIT s’est tournée vers les réseaux neuronaux convolutifs. Ce type de modélisation informatique a été largement utilisé pour modéliser l’intelligence artificielle. système visuel humainPlus récemment, McDermott et d’autres scientifiques ont commencé à l’appliquer également à l’audition.
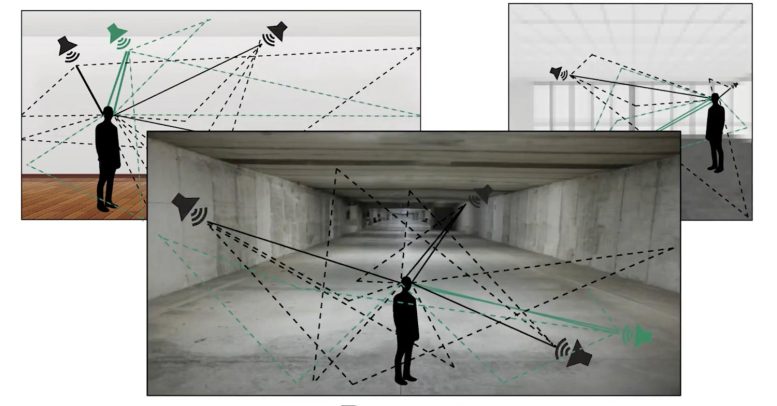
Pour entraîner les modèles, les chercheurs ont créé un monde virtuel dans lequel ils peuvent contrôler la taille de la pièce et les propriétés de réflexion des murs de la pièce. Tous les sons transmis aux modèles provenaient de l’une de ces pièces virtuelles. Crédit : avec l’aimable autorisation des chercheurs
Les réseaux neuronaux convolutifs peuvent être conçus avec de nombreuses architectures différentes. Pour les aider à trouver ceux qui fonctionneraient le mieux pour la localisation, l’équipe du MIT a utilisé un superordinateur qui leur a permis d’entraîner et de tester environ 1 500 modèles différents. Cette recherche a permis d’en identifier 10 qui semblaient les mieux adaptés à la localisation, que les chercheurs ont ensuite entraînés et utilisés pour toutes leurs études ultérieures.
Pour entraîner les modèles, les chercheurs ont créé un monde virtuel dans lequel ils peuvent contrôler la taille de la pièce et les propriétés de réflexion des murs de la pièce. Tous les sons transmis aux modèles provenaient de l’une de ces pièces virtuelles. L’ensemble de plus de 400 sons d’entraînement comprenait des voix humaines, des sons d’animaux, des sons de machines tels que des moteurs de voiture et des sons naturels tels que le tonnerre.
Les chercheurs se sont également assurés que le modèle partait des mêmes informations que celles fournies par les oreilles humaines. L’oreille externe, ou pavillon, possède de nombreux plis qui réfléchissent le son, modifiant les fréquences qui entrent dans l’oreille, et ces réflexions varient en fonction de la provenance du son. Les chercheurs ont simulé cet effet en faisant passer chaque son par une fonction mathématique spécialisée avant de l’intégrer au modèle informatique.
“Cela nous permet de donner au modèle le même type d’information qu’une personne aurait”, explique Francl.
Après avoir formé les modèles, les chercheurs les ont testés dans un environnement réel. Ils ont placé un mannequin avec des microphones dans les oreilles dans une pièce réelle et ont diffusé des sons provenant de différentes directions, puis ont transmis ces enregistrements aux modèles. Les modèles ont obtenu des résultats très similaires à ceux des humains lorsqu’on leur a demandé de localiser ces sons.
“Bien que le modèle ait été entraîné dans un monde virtuel, lorsque nous l’avons évalué, il était capable de localiser des sons dans le monde réel”, explique Francl.
Des modèles similaires
Les chercheurs ont ensuite soumis les modèles à une série de tests que les scientifiques ont utilisés dans le passé pour étudier les capacités de localisation des humains.
En plus d’analyser la différence de temps d’arrivée à l’oreille droite et à l’oreille gauche, le cerveau humain base également ses jugements de localisation sur les différences d’intensité du son qui atteint chaque oreille. Des études antérieures ont montré que le succès de ces deux stratégies varie en fonction de la fréquence du son entrant. Dans la nouvelle étude, l’équipe du MIT a constaté que les modèles montraientce même modèle de sensibilité à la fréquence.
“Le modèle semble utiliser les différences de temps et de niveau entre les deux oreilles de la même manière que les gens, en fonction de la fréquence”, explique McDermott.
Les chercheurs ont également montré que lorsqu’ils rendaient les tâches de localisation plus difficiles, en ajoutant des sources sonores multiples jouées en même temps, les performances des modèles informatiques diminuaient d’une manière qui imitait étroitement les modèles d’échec humains dans les mêmes circonstances.
“À mesure que vous ajoutez des sources de plus en plus nombreuses, vous obtenez un modèle spécifique de déclin de la capacité des humains à évaluer avec précision le nombre de sources présentes et leur capacité à localiser ces sources”, explique Francl. “Les humains semblent être limités à la localisation d’environ trois sources à la fois, et lorsque nous avons effectué le même test sur le modèle, nous avons constaté un modèle de comportement vraiment similaire.”
Comme les chercheurs ont utilisé un monde virtuel pour entraîner leurs modèles, ils ont également pu explorer ce qui se passe lorsque leur modèle apprend à localiser dans différents types de conditions non naturelles. Les chercheurs ont entraîné un ensemble de modèles dans un monde virtuel sans échos, et un autre dans un monde où il n’y avait jamais plus d’un son entendu à la fois. Dans un troisième, les modèles n’ont été exposés qu’à des sons ayant une gamme de fréquences étroite, au lieu de sons naturels.
Lorsque les modèles formés dans ces mondes non naturels ont été évalués sur la même batterie de tests comportementaux, les modèles ont dévié du comportement humain, et les façons dont ils ont échoué variaient en fonction du type d’environnement dans lequel ils avaient été formés. Selon les chercheurs, ces résultats appuient l’idée que les capacités de localisation du cerveau humain sont adaptées aux environnements dans lesquels les humains ont évolué.
Les chercheurs appliquent maintenant ce type de modélisation à d’autres aspects de l’audition, tels que la perception de la hauteur et la reconnaissance de la parole, et pensent qu’il pourrait également être utilisé pour comprendre d’autres phénomènes cognitifs, tels que les limites de ce à quoi une personne peut prêter attention ou se souvenir, dit McDermott.
Référence : “Deep neural network models of sound localization reveal how perception is adapted to real-world environments” par Andrew Francl et Josh H. McDermott, 27 janvier 2022, Nature Human Behaviour.
DOI: 10.1038/s41562-021-01244-z
Cette recherche a été financée par la National Science Foundation et le National Institute on Deafness and Other Communication Disorders.