L’intelligence artificielle a changé la façon de faire de la science en permettant aux chercheurs d’analyser les quantités massives de données que les instruments scientifiques modernes génèrent. Elle peut trouver une aiguille dans un million de bottes de foin d’informations et, grâce à l’apprentissage profond, elle peut apprendre des données elles-mêmes. L’IA accélère les avancées dans la chasse aux gènes, la médecine, la conception de médicaments et la création de composés organiques.
L’apprentissage profond utilise des algorithmes, souvent des réseaux neuronaux entraînés sur de grandes quantités de données, pour extraire des informations de nouvelles données. Il est très différent de l’informatique traditionnelle avec ses instructions étape par étape. Il s’agit plutôt d’un apprentissage à partir de données. L’apprentissage profond est beaucoup moins transparent que la programmation informatique traditionnelle, ce qui laisse des questions importantes : qu’est-ce que le système a appris, que sait-il ?
En tant que professeur de chimie, j’aime concevoir des tests comportant au moins une question difficile qui met à l’épreuve les connaissances des étudiants afin de déterminer s’ils peuvent combiner différentes idées et synthétiser de nouvelles idées et de nouveaux concepts. Nous avons conçu une telle question pour l’enfant-vedette des défenseurs de l’IA, AlphaFold, qui a résolu le problème du repliement des protéines.
Pliage de protéines
Les protéines sont présentes dans tous les organismes vivants. Elles fournissent une structure aux cellules, catalysent des réactions, transportent de petites molécules, digèrent les aliments et font bien d’autres choses encore. Elles sont constituées de longues chaînes d’acides aminés, comme des perles sur un fil. Mais pour qu’une protéine puisse faire son travail dans la cellule, elle doit se tordre et se plier en une structure tridimensionnelle complexe, un processus appelé pliage des protéines. Les protéines mal repliées peuvent entraîner des maladies.
Dans son discours d’acceptation du prix Nobel de chimie en 1972, Christiaan Anfinsen a postulé qu’il devrait être possible de calculer la structure tridimensionnelle d’une protéine à partir de la séquence de ses éléments constitutifs, les acides aminés.
Tout comme l’ordre et l’espacement des lettres de cet article lui donnent un sens et un message, l’ordre des acides aminés détermine l’identité et la forme de la protéine, ce qui entraîne sa fonction.
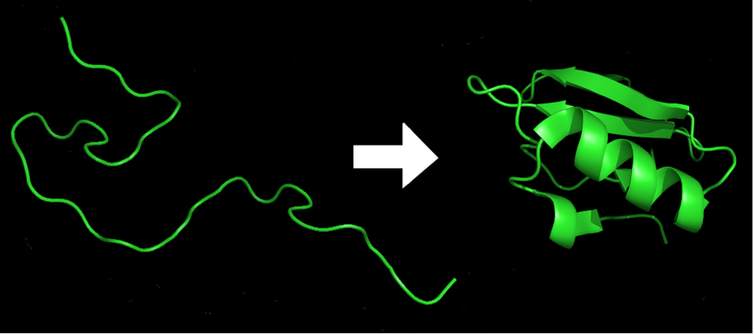
Dans les millisecondes qui suivent la sortie d’une chaîne d’acides aminés (à gauche) du ribosome, celle-ci est repliée dans la forme 3D la moins énergétique (à droite), nécessaire à la fonction de la protéine. Marc Zimmer , CC BY-ND
En raison de la flexibilité inhérente aux blocs de construction des acides aminés, on estime qu’une protéine typique peut adopter 10 à la puissance 300 formes différentes. C’est un nombre énorme, supérieur au nombre d’atomes dans l’univers. Pourtant, en l’espace d’une milliseconde, chaque protéine d’un organisme se replie dans sa forme spécifique, c’est-à-dire dans l’arrangement le plus faible en énergie de toutes les liaisons chimiques qui composent la protéine. Si l’on change un seul acide aminé parmi les centaines d’acides aminés que l’on trouve généralement dans une protéine, celle-ci peut se replier et ne plus fonctionner.
AlphaFold
Pendant 50 ans, les informaticiens ont essayé de résoudre le problème du repliement des protéines, sans grand succès. Puis, en 2016, DeepMind, une filiale d’IA d’Alphabet, la société mère de Google, a lancé son programme AlphaFold. Elle a utilisé la banque de données des protéines comme ensemble d’entraînement, qui contient les structures déterminées expérimentalement de plus de 150 000 protéines.
En moins de cinq ans, AlphaFold a résolu le problème du pliage des protéines, du moins dans sa partie la plus utile, à savoir la détermination de la structure des protéines à partir de leur séquence d’acides aminés. AlphaFold n’explique pas comment les protéines se replient si rapidement et si précisément. Il s’agissait d’une victoire majeure pour l’IA, car non seulement elle bénéficiait d’un énorme prestige scientifique, mais elle constituait également une avancée scientifique majeure susceptible d’affecter la vie de chacun.
Aujourd’hui, grâce à des programmes tels qu’AlphaFold2 et RoseTTAFold, des chercheurs comme moi peuvent déterminer la structure tridimensionnelle des protéines à partir de la séquence des acides aminés qui les composent &ndash ; gratuitement &ndash ; en une heure ou deux. Avant AlphaFold2, nous devions cristalliser les protéines et résoudre les structures par cristallographie aux rayons X, un processus qui prenait des mois et coûtait des dizaines de milliers de dollars par structure.
Nous avons maintenant accès à la base de données AlphaFold sur les structures protéiques, où Deepmind a déposé les structures 3D de presque toutes les protéines présentes chez l’homme, la souris et plus de 20 autres espèces. À ce jour, elle a résolu plus d’un million de structures et prévoit d’ajouter 100 millions de structures supplémentaires rien que cette année. Connaissance des protéinesest monté en flèche. La structure de la moitié de toutes les protéines connues sera probablement documentée d’ici la fin de 2022, parmi lesquelles de nombreuses nouvelles structures uniques associées à de nouvelles fonctions utiles.
Penser comme un chimiste
AlphaFold2 n’a pas été conçu pour prédire comment les protéines interagissent entre elles, mais il a été capable de modéliser comment les protéines individuelles se combinent pour former de grandes unités complexes composées de plusieurs protéines. Nous avions une question difficile à poser à AlphaFold : son ensemble d’entraînement structurel lui avait-il enseigné la chimie ? Pouvait-il dire si les acides aminés allaient réagir les uns avec les autres, un phénomène rare mais important ?
Je suis un chimiste informaticien qui s’intéresse aux protéines fluorescentes. Il s’agit de protéines présentes dans des centaines d’organismes marins comme les méduses et les coraux. Leur éclat peut être utilisé pour éclairer et étudier des maladies.
Il existe 578 protéines fluorescentes dans la banque de données des protéines, dont 10 sont “cassées” et ne sont pas fluorescentes. Les protéines s’attaquent rarement à elles-mêmes, un processus appelé modification post-traductionnelle autocatalytique, et il est très difficile de prévoir quelles protéines réagiront avec elles-mêmes et lesquelles ne le feront pas.
Seul un chimiste ayant une grande connaissance des protéines fluorescentes serait capable d’utiliser la séquence d’acides aminés pour trouver les protéines fluorescentes qui ont la bonne séquence d’acides aminés pour subir les transformations chimiques nécessaires pour les rendre fluorescentes. Lorsque nous avons présenté à AlphaFold2 les séquences de 44 protéines fluorescentes qui ne sont pas dans la banque de données des protéines, il a plié les protéines fluorescentes fixes différemment des protéines cassées.
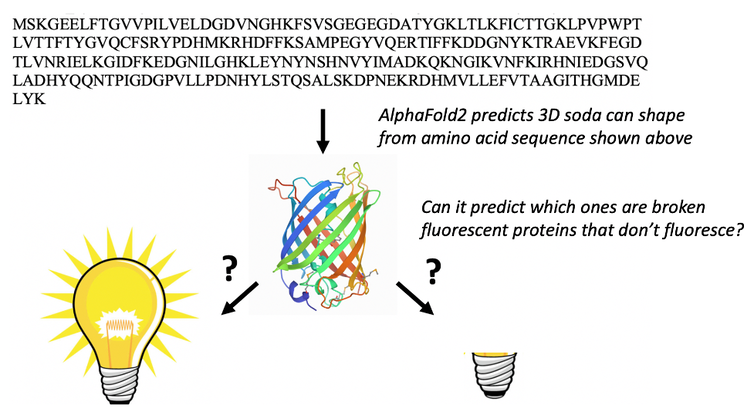
AlphaFold2 peut prendre la séquence d’acides aminés des protéines fluorescentes (lettres en haut) et prédire leur forme de barillet en 3D (milieu). Ce n’est pas surprenant. Ce qui est totalement inattendu, c’est qu’il peut également prédire quelles protéines fluorescentes sont “cassées” et ne peuvent pas être fluorescentes. Marc Zimmer , CC BY-ND
Le résultat nous a stupéfaits : AlphaFold2 avait appris un peu de chimie. Il avait compris quels acides aminés dans les protéines fluorescentes effectuent la chimie qui les fait briller. Nous soupçonnons que l’ensemble d’entraînement de la banque de données sur les protéines et les alignements de séquences multiples permettent à AlphaFold2 de “penser” comme un chimiste et de rechercher les acides aminés nécessaires pour réagir les uns avec les autres et rendre la protéine fluorescente.
Un programme de repliement qui apprend un peu de chimie à partir de son ensemble d’apprentissage a également des implications plus larges. En posant les bonnes questions, que peut-on obtenir d’autres algorithmes d’apprentissage profond ? Les algorithmes de reconnaissance faciale pourraient-ils trouver des marqueurs cachés de maladies ? Les algorithmes conçus pour prédire les habitudes de dépenses des consommateurs pourraient-ils également détecter une propension au vol ou à la tromperie ? Et surtout, cette capacité &ndash ; et des sauts similaires dans la capacité d’autres systèmes d’IA &ndash ; est-elle souhaitable ?