Une nouvelle approche « de bon sens » de la vision par ordinateur permet à l’intelligence artificielle d’interpréter les scènes avec plus de précision que les autres systèmes.
Les systèmes de vision par ordinateur font parfois des déductions sur une scène qui vont à l’encontre du bon sens. Par exemple, si un robot traitait une scène d’une table à dîner, il pourrait ignorer complètement un bol visible par tout observateur humain, estimer qu’une assiette flotte au-dessus de la table ou percevoir à tort qu’une fourchette pénètre dans un bol plutôt que appuyé contre elle.
Déplacez ce système de vision par ordinateur vers une voiture autonome et les enjeux deviennent beaucoup plus importants – par exemple, de tels systèmes n’ont pas réussi à détecter les véhicules d’urgence et les piétons traversant la rue.
Pour surmonter ces erreurs, AVEC les chercheurs ont développé un cadre qui aide les machines à voir le monde plus comme le font les humains. Leur nouveau système d’intelligence artificielle pour analyser des scènes apprend à percevoir des objets du monde réel à partir de quelques images seulement et perçoit les scènes en fonction de ces objets appris.
Les chercheurs ont construit le cadre à l’aide de la programmation probabiliste, une approche d’IA qui permet au système de comparer les objets détectés aux données d’entrée, pour voir si les images enregistrées à partir d’une caméra correspondent probablement à une scène candidate. L’inférence probabiliste permet au système de déduire si les discordances sont probablement dues au bruit ou à des erreurs dans l’interprétation de la scène qui doivent être corrigées par un traitement ultérieur.

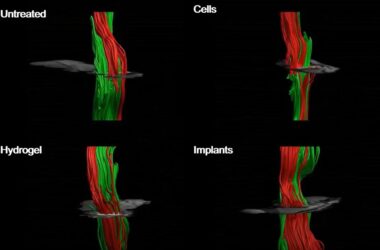
Cette image montre comment 3DP3 (rangée du bas) déduit des estimations de pose plus précises des objets à partir des images d’entrée (rangée du haut) que les systèmes d’apprentissage en profondeur (rangée du milieu). Crédit : Avec l’aimable autorisation des chercheurs
Cette sauvegarde de bon sens permet au système de détecter et de corriger de nombreuses erreurs qui empoisonnent les approches de « deep-learning » qui ont également été utilisées pour la vision par ordinateur. La programmation probabiliste permet également de déduire des relations de contact probables entre les objets de la scène et d’utiliser un raisonnement de bon sens à propos de ces contacts pour déduire des positions plus précises pour les objets.
« Si vous ne connaissez pas les relations de contact, alors vous pourriez dire qu’un objet flotte au-dessus de la table – ce serait une explication valable. En tant qu’humains, il est évident pour nous que cela est physiquement irréaliste et que l’objet posé sur la table est une pose plus probable de l’objet. Parce que notre système de raisonnement est conscient de ce type de connaissance, il peut déduire des poses plus précises. C’est un aperçu clé de ce travail », déclare l’auteur principal Nishad Gothoskar, doctorant en génie électrique et informatique (EECS) avec le Probabilistic Computing Project.
En plus d’améliorer la sécurité des voitures autonomes, ces travaux pourraient améliorer les performances des systèmes de perception informatiques qui doivent interpréter des arrangements compliqués d’objets, comme un robot chargé de nettoyer une cuisine encombrée.
Les co-auteurs de Gothoskar incluent Marco Cusumano-Towner, récemment diplômé en doctorat de l’EECS ; ingénieur de recherche Ben Zinberg ; l’étudiant invité Matin Ghavamizadeh ; Falk Pollok, ingénieur logiciel au MIT-IBM Watson AI Lab ; Austin Garrett, récent diplômé de la maîtrise EECS; Dan Gutfreund, chercheur principal au MIT-IBM Watson AI Lab ; Joshua B. Tenenbaum, professeur Paul E. Newton en développement de carrière en sciences cognitives et calcul au Département des sciences du cerveau et des sciences cognitives (BCS) et membre du Laboratoire d’informatique et d’intelligence artificielle ; et l’auteur principal Vikash K. Mansinghka, chercheur principal et chef du projet de calcul probabiliste de BCS. La recherche est présentée à la Conférence sur les systèmes de traitement de l’information neuronale en décembre.
Un souffle du passé
Pour développer le système, appelé « Perception de scène 3D via la programmation probabiliste (3DP3) », les chercheurs se sont inspirés d’un concept des premiers jours de la recherche sur l’IA, à savoir que la vision par ordinateur peut être considérée comme « l’inverse » de l’infographie.
L’infographie se concentre sur la génération d’images basées sur la représentation d’une scène ; la vision par ordinateur peut être considérée comme l’inverse de ce processus. Gothoskar et ses collaborateurs ont rendu cette technique plus facile à apprendre et évolutive en l’intégrant dans un cadre construit à l’aide de la programmation probabiliste.
« La programmation probabiliste nous permet d’écrire nos connaissances sur certains aspects du monde d’une manière qu’un ordinateur peut interpréter, mais en même temps, elle nous permet d’exprimer ce que nous ne savons pas, l’incertitude. Ainsi, le système est capable d’apprendre automatiquement à partir des données et également de détecter automatiquement lorsque les règles ne tiennent pas », explique Cusumano-Towner.
Dans ce cas, le modèle est codé avec des connaissances préalables sur les scènes 3D. Par exemple, 3DP3 « sait » que les scènes sont composées d’objets différents et que ces objets reposent souvent à plat les uns sur les autres, mais ils peuvent ne pas toujours être dans des relations aussi simples. Cela permet au modèle de raisonner sur une scène avec plus de bon sens.
Apprentissage des formes et des scènes
Pour analyser une image d’une scène, 3DP3 apprend d’abord les objets de cette scène. Après avoir montré seulement cinq images d’un objet, chacune prise sous un angle différent, 3DP3 apprend la forme de l’objet et estime le volume qu’il occuperait dans l’espace.
« Si je vous montre un objet sous cinq perspectives différentes, vous pouvez créer une assez bonne représentation de cet objet. Vous comprendriez sa couleur, sa forme et vous seriez capable de reconnaître cet objet dans de nombreuses scènes différentes », explique Gothoskar.
Mansinghka ajoute : « Il s’agit de beaucoup moins de données que les approches d’apprentissage en profondeur. Par exemple, le système de détection d’objets neuronaux Dense Fusion nécessite des milliers d’exemples de formation pour chaque type d’objet. En revanche, 3DP3 ne nécessite que quelques images par objet et signale une incertitude sur les parties de la forme de chaque objet qu’il ne connaît pas.
Le système 3DP3 génère un graphique pour représenter la scène, où chaque objet est un nœud et les lignes qui relient les nœuds indiquent quels objets sont en contact les uns avec les autres. Cela permet à 3DP3 de produire une estimation plus précise de la disposition des objets. (Les approches d’apprentissage en profondeur reposent sur des images de profondeur pour estimer les poses d’objets, mais ces méthodes ne produisent pas de structure graphique des relations de contact, de sorte que leurs estimations sont moins précises.)
Des modèles de référence plus performants
Les chercheurs ont comparé 3DP3 avec plusieurs systèmes d’apprentissage en profondeur, tous chargés d’estimer les poses d’objets 3D dans une scène.
Dans presque tous les cas, 3DP3 a généré des poses plus précises que les autres modèles et a fonctionné bien mieux lorsque certains objets obstruaient partiellement d’autres. Et 3DP3 n’avait besoin de voir que cinq images de chaque objet, tandis que chacun des modèles de base qu’il surpassait avait besoin de milliers d’images pour l’entraînement.
Lorsqu’il est utilisé en conjonction avec un autre modèle, 3DP3 a pu améliorer son précision. Par exemple, un modèle d’apprentissage en profondeur peut prédire qu’un bol flotte légèrement au-dessus d’une table, mais parce que 3DP3 a connaissance des relations de contact et peut voir qu’il s’agit d’une configuration improbable, il est capable d’apporter une correction en alignant le bol avec le tableau.
« J’ai trouvé surprenant de voir à quel point les erreurs du deep learning pouvaient parfois être importantes, en produisant des représentations de scènes où les objets ne correspondaient vraiment pas à ce que les gens percevraient. J’ai également trouvé surprenant que seul un peu d’inférence basée sur un modèle dans notre programme probabiliste causal soit suffisant pour détecter et corriger ces erreurs. Bien sûr, il reste encore un long chemin à parcourir pour le rendre suffisamment rapide et robuste pour les systèmes de vision en temps réel difficiles – mais pour la première fois, nous voyons une programmation probabiliste et des modèles causaux structurés améliorer la robustesse par rapport à l’apprentissage en profondeur sur la 3D dure. repères de vision », dit Mansinghka.
À l’avenir, les chercheurs aimeraient pousser le système plus loin afin qu’il puisse connaître un objet à partir d’une seule image ou d’une seule image dans un film, puis être capable de détecter cet objet de manière robuste dans différentes scènes. Ils aimeraient également explorer l’utilisation de 3DP3 pour collecter des données d’entraînement pour un réseau de neurones. Il est souvent difficile pour les humains d’étiqueter manuellement des images avec une géométrie 3D, donc 3DP3 pourrait être utilisé pour générer des étiquettes d’images plus complexes.
Le système 3DP3 « combine une modélisation graphique basse fidélité avec un raisonnement de bon sens pour corriger les grandes erreurs d’interprétation de scènes commises par les réseaux neuronaux d’apprentissage en profondeur. Ce type d’approche pourrait avoir une large applicabilité car il traite des modes de défaillance importants de l’apprentissage en profondeur. L’accomplissement des chercheurs du MIT montre également comment la technologie de programmation probabiliste précédemment développée sous DARPALe programme de programmation probabiliste pour l’avancement de l’apprentissage machine (PPAML) peut être appliqué pour résoudre les problèmes centraux de l’IA de bon sens dans le cadre du programme Machine Common Sense (MCS) actuel de la DARPA », déclare Matt Turek, responsable du programme DARPA pour le programme Machine Common Sense, qui n’a pas participé à cette recherche, bien que le programme ait financé en partie l’étude.
Référence : « 3DP3 : 3D Scene Perception via Probabilistic Programming » par Nishad Gothoskar, Marco Cusumano-Towner, Ben Zinberg, Matin Ghavamizadeh, Falk Pollok, Austin Garrett, Joshua B. Tenenbaum, Dan Gutfreund et Vikash K. Mansinghka, 30 octobre 2021, Informatique > Vision par ordinateur et reconnaissance de formes.
arXiv:2111.00312
Parmi les autres bailleurs de fonds figurent la collaboration de la Singapore Defense Science and Technology Agency avec le MIT Schwarzman College of Computing, le Probabilistic Computing Center d’Intel, le MIT-IBM Watson AI Lab, la Aphorism Foundation et la Siegel Family Foundation.