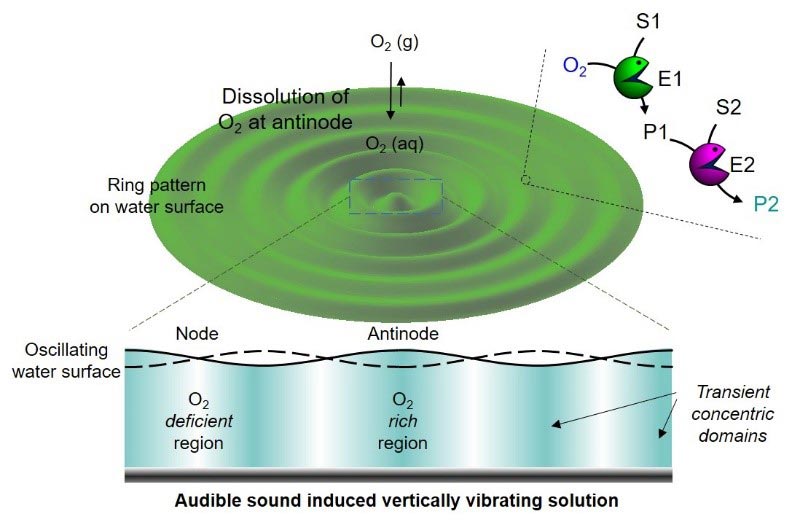
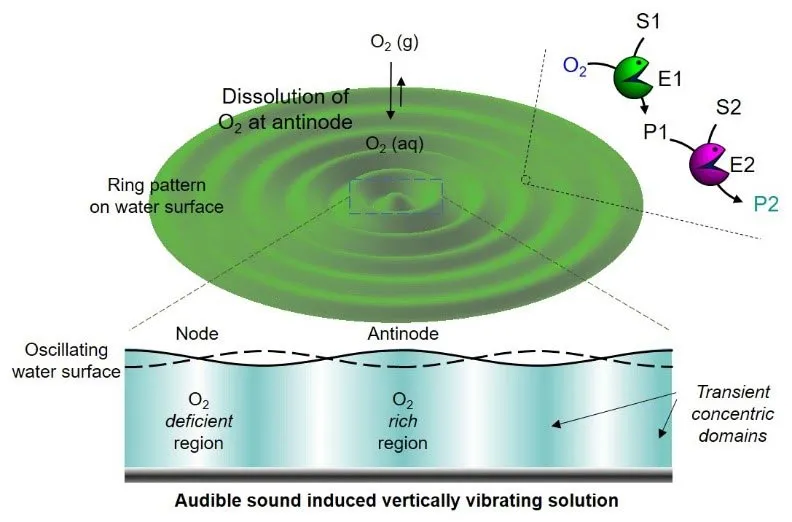
Figure 1. Génération de domaines transitoires induite par un son audible et réseaux de réactions en cascade contrôlés spatio-temporellement. Crédit : Institut des sciences fondamentales
La compartimentation transitoire générée par le son audible permet de contrôler spatio-temporellement les réactions enzymatiques.
La régulation spatio-temporelle des réactions enzymatiques multi-étapes par la compartimentation est essentielle dans les études qui imitent les systèmes naturels tels que les cellules et les organites. Jusqu’à présent, les scientifiques ont utilisé des liposomes, des vésicules ou des polymersomes pour séparer physiquement les différentes enzymes dans des compartiments, qui fonctionnent comme des “organites artificiels”. Mais aujourd’hui, une équipe de chercheurs dirigée par le directeur KIM Kimoon du Centre d’auto-assemblage et de complexité de l’Institut des sciences fondamentales de Pohang, en Corée du Sud, a réussi à démontrer la même régulation spatio-temporelle des réactions chimiques en utilisant uniquement un son audible, ce qui est complètement différent des méthodes précédentes mentionnées ci-dessus.
Bien que le son ait été largement utilisé en physique, en science des matériaux et dans d’autres domaines, il a rarement été utilisé en chimie. En particulier, le son audible (dans la gamme de 20 à 20 000 Hz) n’a pas été utilisé jusqu’à présent dans les réactions chimiques en raison de sa faible énergie. Cependant, pour la première fois, le même groupe de l’IBS avait déjà démontré avec succès la régulation spatio-temporelle de réactions chimiques par une dissolution sélective de gaz atmosphériques via des ondes stationnaires générées par un son audible en 2020.

Figure 2. Contrôle spatio-temporel de la réaction en cascade glucose/GOx/HRP/ABTS médiée par un son audible. (A) Représentation schématique de la réaction en cascade glucose/GOx/HRP/ABTS. (B) Modèle de forme aléatoire généré sans l’application d’un son audible. (C) Changements en fonction du temps d’un modèle d’anneau concentrique obtenu en appliquant un son audible (40 Hz). Crédit : Institut des sciences fondamentales
Plus tard, ils ont observé de près le mouvement de la solution induit par le son audible et ont constaté que la solution était séparée et non mélangée en raison de la région du nœud de l’onde, comme si les différentes couches étaient bloquées par un mur invisible. Ils ont appelé ce domaine transitoire de la solution créé par le son audible “pseudo-compartimentage”, et l’ont utilisé pour contrôler les réseaux de réactions en cascade à base d’enzymes dans une solution. Dans ce phénomène, les flux de fluides qui sont induits dans un récipient vibrant de haut en bas par un son audible ne se mélangent pas les uns aux autres autour du nœud de l’onde, et de ce fait, la solution devient naturellement compartimentée.
Cette nouvelle découverte a incité le groupe à utiliser ce phénomène pour tenter de réguler spatio-temporellement des réactions enzymatiques à plusieurs étapes. Normalement, pour ce faire, il faut créer des compartiments artificiels en utilisant des lipides ou des polymères sont généralement utilisés, mais le groupe de Kim a montré que cela peut être possible en utilisant uniquement un son audible. Pour y parvenir, ils ont conçu un système astucieux en tirant parti du fait que l’oxygène présent dans l’air n’est dissous que dans la région antinodale de la solution vibrante (figure 1).

Figure 3. (A) Son audible et contrôle spatio-temporel de l’assemblage des nanoparticules d’or par l’enzyme. Motifs concentriques colorés et images TEM prises dans chaque région du motif. (B) Hydrogel à motifs de nanoparticules (à gauche) et son utilisation pour la croissance sélective de cellules (à droite). Dans l’image au microscope fluorescent, les points rouges représentent des cellules HeLa sur la surface de l’hydrogel à motifs. Crédit : Institut des sciences fondamentales
Pour tester ce système, le groupe de Kim a réalisé une réaction enzymatique en plusieurs étapes composée de glucose oxydase (GOx) et de peroxydase de raifort (HRP). Dans la première étape, l’enzyme GOx catalyse l’oxydation du glucose et produit du peroxyde d’hydrogène. Ce peroxyde est ensuite utilisé par l’enzyme HRP pour alimenter la deuxième étape, qui implique l’oxydation du colorant ABTS incolore en radical ABTS de couleur cyan. Les chercheurs sauront que leur système fonctionne comme prévu si la couleur cyan apparaît à des endroits spécifiques de la solution.
Comme prévu, les auteurs ont pu observer visuellement des anneaux concentriques de couleur cyan, ce qui a confirmé qu’ils avaient réussi à contrôler spatio-temporellement la réaction en cascade GOx-HRP en utilisant uniquement un son audible (Figure 2). Les auteurs ont également montré que cette méthode peut être étendue au contrôle de la croissance in situ induite par l’oxydoréduction ou à l’auto-assemblage sensible au pH de nanoparticules dans des domaines spatio-temporels présents dans la solution. (Figure 3A). En outre, les auteurs ont également présenté la préparation d’hydrogels à motifs de nanoparticules, qui ont été fabriqués à partir d’un mélange d’eau et d’oxygène.contenaient des particules auto-assemblées uniquement dans des régions sélectionnées. Ces gels peuvent être utilisés dans des plateformes de croissance cellulaire à région spécifique (figure 3B).
“Cette nouvelle approche utilisant un son audible fournira une stratégie totalement nouvelle et fiable pour contrôler les processus chimiques au sein de pseudo-compartiments prévisibles mais générés de manière transitoire dans une solution”, explique le directeur Kim.
Référence : “Cascade reaction networks within audible sound induced transient domains in a solution” par Prabhu Dhasaiyan, Tanwistha Ghosh, Hong-Guen Lee, Yeonsang Lee, Ilha Hwang, Rahul Dev Mukhopadhyay, Kyeng Min Park, Seungwon Shin, In Seok Kang, et Kimoon Kim, 2 mai 2022, Nature Communications.
DOI: 10.1038/s41467-022-30124-x