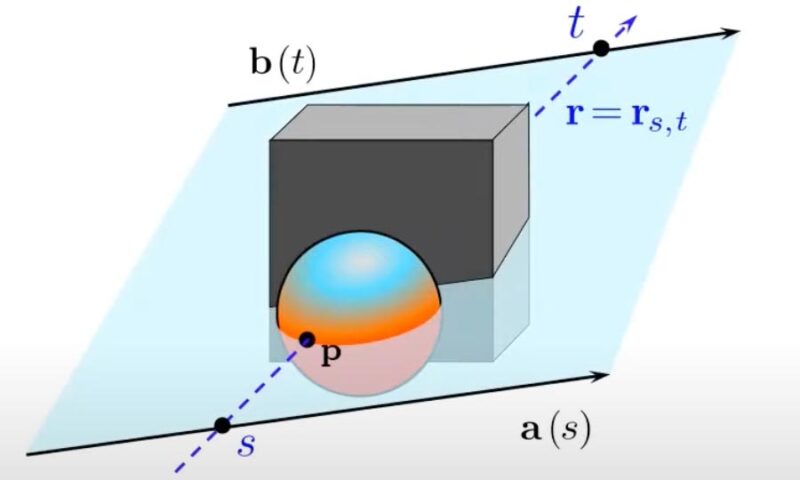
Pour représenter une scène 3D à partir d’une image 2D, un réseau de champ lumineux code le champ lumineux à 360 degrés de la scène 3D dans un réseau neuronal qui mappe directement chaque rayon de caméra à la couleur observée par ce rayon. Crédit : Avec l’aimable autorisation des chercheurs
Le nouveau système d’apprentissage automatique peut générer une scène 3D à partir d’une image environ 15 000 fois plus rapidement que les autres méthodes.
Les humains sont assez bons pour regarder une seule image bidimensionnelle et comprendre la scène tridimensionnelle complète qu’elle capture. Les agents d’intelligence artificielle ne le sont pas.
Pourtant, une machine qui doit interagir avec des objets dans le monde – comme un robot conçu pour récolter des récoltes ou assister une intervention chirurgicale – doit être capable de déduire les propriétés d’une scène 3D à partir des observations des images 2D sur lesquelles elle est formée.
Alors que les scientifiques ont réussi à utiliser des réseaux de neurones pour déduire des représentations de scènes 3D à partir d’images, ces méthodes d’apprentissage automatique ne sont pas assez rapides pour les rendre réalisables pour de nombreuses applications du monde réel.
Une nouvelle technique démontrée par des chercheurs de AVEC et ailleurs est capable de représenter des scènes 3D à partir d’images environ 15 000 fois plus rapidement que certains modèles existants.
La méthode représente une scène sous la forme d’un champ lumineux à 360 degrés, qui est une fonction qui décrit tous les rayons lumineux dans un espace 3D, circulant à travers chaque point et dans chaque direction. Le champ lumineux est codé dans un réseau de neurones, ce qui permet un rendu plus rapide de la scène 3D sous-jacente à partir d’une image.
Les réseaux de champ lumineux (LFN) que les chercheurs ont développés peuvent reconstruire un champ lumineux après une seule observation d’une image, et ils sont capables de restituer des scènes 3D à des fréquences d’images en temps réel.
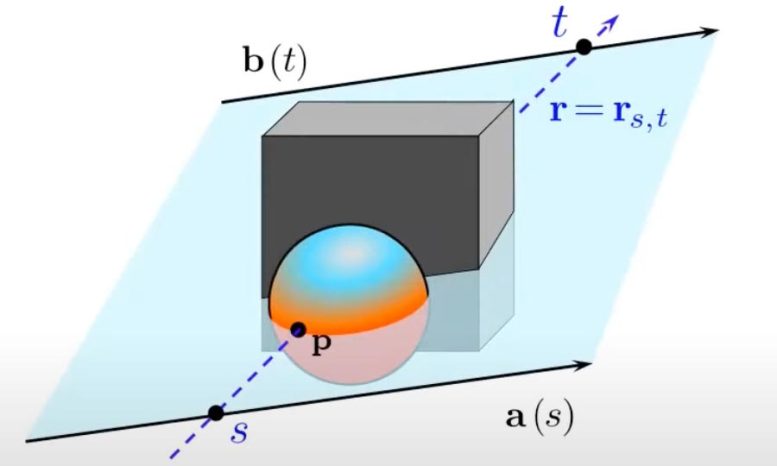
Étant donné une image d’une scène 3D et un rayon lumineux, un réseau de champ lumineux peut calculer des informations riches sur la géométrie de la scène 3D sous-jacente. Crédit : Image : avec l’aimable autorisation des chercheurs
« La grande promesse de ces représentations de scènes neuronales, en fin de compte, est de les utiliser dans des tâches de vision. Je vous donne une image et à partir de cette image, vous créez une représentation de la scène, puis tout ce que vous voulez raisonner à propos de vous le faites dans l’espace de cette scène 3D », explique Vincent Sitzmann, post-doctorant au Laboratoire d’informatique et d’intelligence artificielle. (CSAIL) et co-auteur principal de l’article.
Sitzmann a écrit l’article avec le co-auteur principal Semon Rezchikov, post-doctorant à l’Université Harvard ; William T. Freeman, professeur Thomas et Gerd Perkins de génie électrique et d’informatique et membre du CSAIL ; Joshua B. Tenenbaum, professeur de sciences cognitives computationnelles au Département des sciences du cerveau et des sciences cognitives et membre du CSAIL ; et l’auteur principal Frédo Durand, professeur de génie électrique et d’informatique et membre du CSAIL. La recherche sera présentée à la conférence sur les systèmes de traitement de l’information neuronale ce mois-ci.
Cartographie des rayons
En vision par ordinateur et en infographie, le rendu d’une scène 3D à partir d’une image implique la cartographie de milliers, voire de millions de rayons de caméra. Pensez aux rayons d’une caméra comme des faisceaux laser jaillissant d’un objectif de caméra et frappant chaque pixel d’une image, un rayon par pixel. Ces modèles informatiques doivent déterminer la couleur du pixel frappé par chaque rayon de caméra.
De nombreuses méthodes actuelles y parviennent en prélevant des centaines d’échantillons sur la longueur de chaque rayon de caméra au fur et à mesure qu’il se déplace dans l’espace, ce qui est un processus coûteux en calcul qui peut entraîner un rendu lent.
Au lieu de cela, un LFN apprend à représenter le champ lumineux d’une scène 3D, puis mappe directement chaque rayon de caméra dans le champ lumineux à la couleur observée par ce rayon. Un LFN exploite les propriétés uniques des champs lumineux, qui permettent le rendu d’un rayon après une seule évaluation, de sorte que le LFN n’a pas besoin de s’arrêter le long d’un rayon pour exécuter des calculs.
« Avec d’autres méthodes, lorsque vous faites ce rendu, vous devez suivre le rayon jusqu’à ce que vous trouviez la surface. Vous devez faire des milliers d’échantillons, car c’est ce que signifie trouver une surface. Et vous n’avez même pas encore fini car il peut y avoir des choses complexes comme la transparence ou les reflets. Avec un champ lumineux, une fois que vous avez reconstruit le champ lumineux, ce qui est un problème compliqué, le rendu d’un seul rayon ne prend qu’un seul échantillon de la représentation, car la représentation mappe directement un rayon sur sa couleur », explique Sitzmann.
Le LFN classe chaque rayon de caméra à l’aide de ses « coordonnées de Plücker », qui représentent une ligne dans l’espace 3D en fonction de sa direction et de sa distance par rapport à son point d’origine. Le système calcule les coordonnées Plücker de chaque rayon de caméra au point où il atteint un pixel pour restituer une image.
En cartographiant chaque rayon à l’aide des coordonnées de Plücker, le LFN est également capable de calculer la géométrie de la scène en raison de l’effet de parallaxe. La parallaxe est la différence de position apparente d’un objet vu à partir de deux lignes de visée différentes. Par exemple, si vous bougez la tête, les objets plus éloignés semblent bouger moins que les objets plus proches. Le LFN peut indiquer la profondeur des objets dans une scène en raison de la parallaxe et utilise cette information pour coder la géométrie d’une scène ainsi que son apparence.
Mais pour reconstruire les champs lumineux, le réseau de neurones doit d’abord connaître les structures des champs lumineux. Les chercheurs ont donc formé leur modèle avec de nombreuses images de scènes simples de voitures et de chaises.
« Il existe une géométrie intrinsèque des champs lumineux, ce que notre modèle essaie d’apprendre. Vous pourriez vous inquiéter du fait que les champs lumineux des voitures et des chaises sont si différents que vous ne pouvez pas apprendre de points communs entre eux. Mais il s’avère que si vous ajoutez plus de types d’objets, tant qu’il y a une certaine homogénéité, vous obtenez une idée de mieux en mieux à quoi ressemblent les champs de lumière des objets généraux, vous pouvez donc généraliser sur les classes », explique Rezchikov.
Une fois que le modèle apprend la structure d’un champ lumineux, il peut restituer une scène 3D à partir d’une seule image en entrée.
Rendu rapide
Les chercheurs ont testé leur modèle en reconstruisant des champs lumineux à 360 degrés de plusieurs scènes simples. Ils ont découvert que les LFN étaient capables de restituer des scènes à plus de 500 images par seconde, environ trois ordres de grandeur plus rapidement que les autres méthodes. De plus, les objets 3D rendus par les LFN étaient souvent plus nets que ceux générés par d’autres modèles.
Un LFN est également moins gourmand en mémoire, ne nécessitant qu’environ 1,6 Mo de stockage, contre 146 Mo pour une méthode de base courante.
« Les champs de lumière ont été proposés auparavant, mais à l’époque, ils étaient insolubles. Maintenant, avec ces techniques que nous avons utilisées dans cet article, pour la première fois, vous pouvez à la fois représenter ces champs lumineux et travailler avec ces champs lumineux. C’est une convergence intéressante des modèles mathématiques et des modèles de réseaux neuronaux que nous avons développés qui se réunissent dans cette application de représentation de scènes afin que les machines puissent raisonner à leur sujet », explique Sitzmann.
À l’avenir, les chercheurs aimeraient rendre leur modèle plus robuste afin qu’il puisse être utilisé efficacement pour des scènes complexes du monde réel. Une façon de faire avancer les LFN est de se concentrer uniquement sur la reconstruction de certaines zones du champ lumineux, ce qui pourrait permettre au modèle de fonctionner plus rapidement et de mieux fonctionner dans des environnements réels, explique Sitzmann.
« Le rendu neuronal a récemment permis le rendu photoréaliste et l’édition d’images à partir d’un ensemble clairsemé de vues d’entrée. Malheureusement, toutes les techniques existantes sont très coûteuses en calcul, ce qui empêche les applications qui nécessitent un traitement en temps réel, comme la vidéoconférence. Ce projet fait un grand pas vers une nouvelle génération d’algorithmes de rendu neuronal efficaces et mathématiquement élégants », déclare Gordon Wetzstein, professeur agrégé de génie électrique à l’Université de Stanford, qui n’a pas participé à cette recherche. “Je prévois qu’il aura des applications répandues, dans l’infographie, la vision par ordinateur et au-delà.”
Référence : « Light Field Networks : Neural Scene Representations with Single-Evaluation Rendering » par Vincent Sitzmann, Semon Rezchikov, William T. Freeman, Joshua B. Tenenbaum et Fredo Durand, 4 juin 2021, Informatique > Vision par ordinateur et reconnaissance de formes.
arXiv:2106.02634
Ce travail est soutenu par la National Science Foundation, l’Office of Naval Research, Mitsubishi, la Defense Advanced Research Projects Agency et la Singapore Defense Science and Technology Agency.


