Par

L’apprentissage automatique est le processus consistant à utiliser des ordinateurs pour détecter des modèles dans des ensembles de données massifs, puis faire des prédictions en fonction de ce que l’ordinateur apprend de ces modèles. Cela fait de l’apprentissage automatique un type spécifique et étroit d’intelligence artificielle. L’intelligence artificielle complète implique des machines capables d’exécuter des capacités que nous associons à l’esprit des êtres humains et des animaux intelligents, telles que la perception, l’apprentissage et la résolution de problèmes.
Tout l’apprentissage automatique est basé sur des algorithmes. En général, les algorithmes sont des ensembles d’instructions spécifiques qu’un ordinateur utilise pour résoudre des problèmes. En apprentissage automatique, les algorithmes sont des règles permettant d’analyser des données à l’aide de statistiques. Les systèmes d’apprentissage automatique utilisent ces règles pour identifier les relations entre les entrées de données et les sorties souhaitées, généralement des prédictions. Pour commencer, les scientifiques fournissent aux systèmes d’apprentissage automatique un ensemble de données d’entraînement. Les systèmes appliquent leurs algorithmes à ces données pour s’entraîner à analyser les entrées similaires qu’ils recevront à l’avenir.
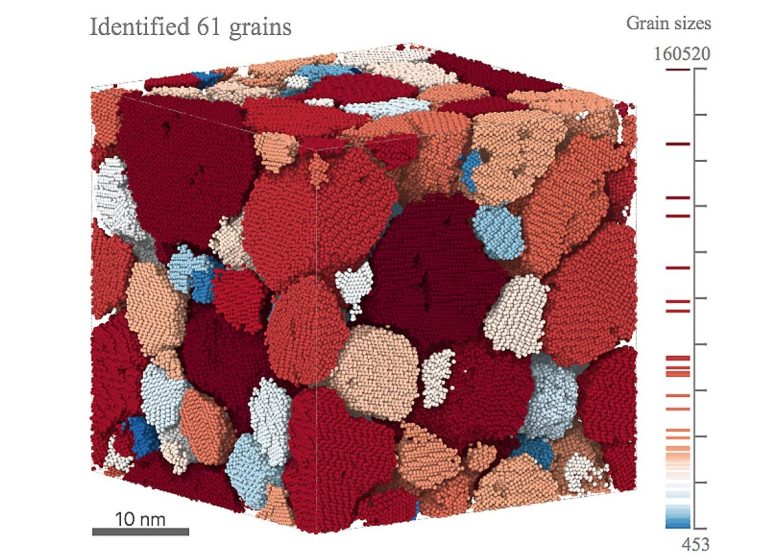
L’apprentissage automatique peut analyser rapidement des phénomènes complexes comme cette simulation de cristaux de glace. L’apprentissage automatique a combiné la classification des formes, le traitement d’images et l’analyse statistique pour identifier et caractériser les grains de glace. Crédit : Image reproduite avec l’aimable autorisation du Laboratoire national d’Argonne
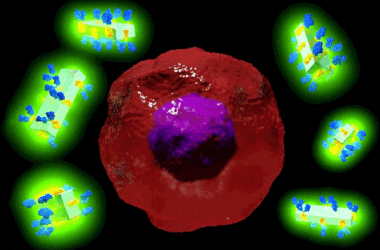
L’un des domaines dans lesquels l’apprentissage automatique est très prometteur est la détection du cancer en imagerie par tomographie par ordinateur (CT). Tout d’abord, les chercheurs assemblent autant d’images CT que possible à utiliser comme données d’apprentissage. Certaines de ces images montrent des tissus avec des cellules cancéreuses et d’autres des tissus sains. Les chercheurs rassemblent également des informations sur ce qu’il faut rechercher dans une image pour identifier le cancer. Par exemple, cela pourrait inclure à quoi ressemblent les limites des tumeurs cancéreuses. Ensuite, ils créent des règles sur la relation entre les données des images et ce que les médecins savent sur l’identification du cancer. Ensuite, ils donnent ces règles et les données d’entraînement au système d’apprentissage automatique. Le système utilise les règles et les données d’apprentissage pour apprendre à reconnaître les tissus cancéreux. Enfin, le système obtient les images CT d’un nouveau patient. En utilisant ce qu’il a appris, le système décide quelles images montrent des signes de cancer, plus rapidement que n’importe quel humain. Les médecins pourraient utiliser les prédictions du système pour aider à décider si un patient a un cancer et comment le traiter.
La façon dont les données d’entraînement sont configurées divise les systèmes d’apprentissage automatique en deux grands types : supervisé et non supervisé. Si les données d’entraînement sont étiquetées, le système est supervisé. Les données étiquetées indiquent au système quelles sont les données. Par exemple, les images CT pourraient être étiquetées pour indiquer des lésions cancéreuses ou des tumeurs à côté de tissus sains. Fondamentalement, cela signifie que le système d’apprentissage automatique apprend par l’exemple. L’étiquetage des données peut prendre beaucoup de temps pour les grandes quantités de données requises pour les ensembles de données d’apprentissage.
Si les données d’entraînement ne sont pas étiquetées, le système d’apprentissage automatique n’est pas supervisé. Dans l’exemple de l’analyse du cancer, un système d’apprentissage automatique non supervisé recevrait un grand nombre de tomodensitogrammes et d’informations sur les types de tumeurs, puis serait laissé à lui-même pour apprendre ce qu’il faut rechercher pour reconnaître le cancer. Cela libère les êtres humains du besoin d’étiqueter les données utilisées dans le processus de formation. L’inconvénient de l’apprentissage non supervisé est que les résultats peuvent ne pas être aussi précis en raison du manque d’étiquettes explicites.
Certains systèmes d’apprentissage automatique peuvent améliorer leurs capacités en fonction des commentaires reçus sur les prédictions. C’est ce qu’on appelle des systèmes d’apprentissage automatique par renforcement. Par exemple, le système pourrait être informé des résultats d’autres tests effectués par les médecins pour savoir si les patients ont ou non un cancer. Le système pourrait alors peaufiner ses algorithmes pour produire des prédictions plus précises à l’avenir.
Faits rapides
- Le plus récent des superordinateurs du DOE—Summit at Oak Ridge National Laboratory—a une architecture particulièrement bien adaptée aux applications d’intelligence artificielle.
- L’apprentissage automatique permet aux scientifiques d’analyser des quantités de données qui étaient auparavant inaccessibles.
- Des chercheurs financés par le DOE ont utilisé l’apprentissage automatique pour développer un nouveau dépistage du cancer, mieux comprendre les propriétés de l’eau et piloter des expériences de manière autonome.
- L’apprentissage automatique basé sur la physique utilise des réseaux de neurones profonds qui peuvent être entraînés pour incorporer des lois spécifiques de la physique afin de résoudre des tâches d’apprentissage supervisé et des problèmes scientifiques.
- Les algorithmes d’apprentissage automatique ne sont pas une solution miracle. Le développement de systèmes d’apprentissage automatique est sensible aux erreurs humaines et aux biais et nécessite la même conception minutieuse que l’ingénierie logicielle.
Bureau des sciences du DOE : Contributions à l’apprentissage automatique
Le Department of Energy Office of Science soutient la recherche sur l’apprentissage automatique par le biais de son programme Advanced Scientific Computing Research (ASCR). ASCR dispose d’un portefeuille de gestion de données, d’analyse de données, de technologie informatique et de recherches connexes qui contribuent tous à l’apprentissage automatique et à l’intelligence artificielle. Dans le cadre de ce portefeuille, le DOE possède certains des supercalculateurs les plus performants au monde.
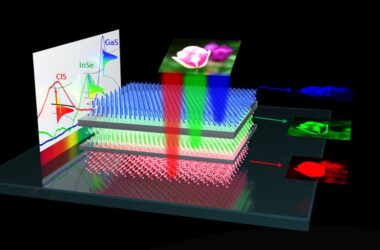
Le DOE Office of Science dans son ensemble s’est engagé à utiliser l’apprentissage automatique pour soutenir la recherche scientifique. La science dépend des mégadonnées, et les installations des utilisateurs de l’Office of Science, telles que les accélérateurs de particules et les sources lumineuses à rayons X, en génèrent des montagnes. Grâce à l’apprentissage automatique, les chercheurs identifient des modèles ou des conceptions dans les données de ces installations qui sont difficiles ou impossibles à détecter pour les humains, à des vitesses qui sont des centaines à des milliers de fois plus rapides que les techniques d’analyse de données traditionnelles.