
Dans un article publié le 11 mars 2022 dans la revue Sciences Advances, des chercheurs du département de chimie et du département de physique et d’astronomie de l’Université de Californie, Irvine ont révélé de nouveaux détails sur une enzyme clé qui rend DNA sequencing possible. The finding is a leap forward into the era of personalized medicine when doctors will be able to design treatments based on the genomes of individual patients.
“Enzymes make life possible by catalyzing chemical transformations that otherwise would just take too long for an organism,” said Greg Weiss, UCI professor of chemistry and a co-corresponding author of the new study. “One of the transformations we’re really interested in is essential for all life on the planet – it’s the process by which DNA is copied and repaired.”
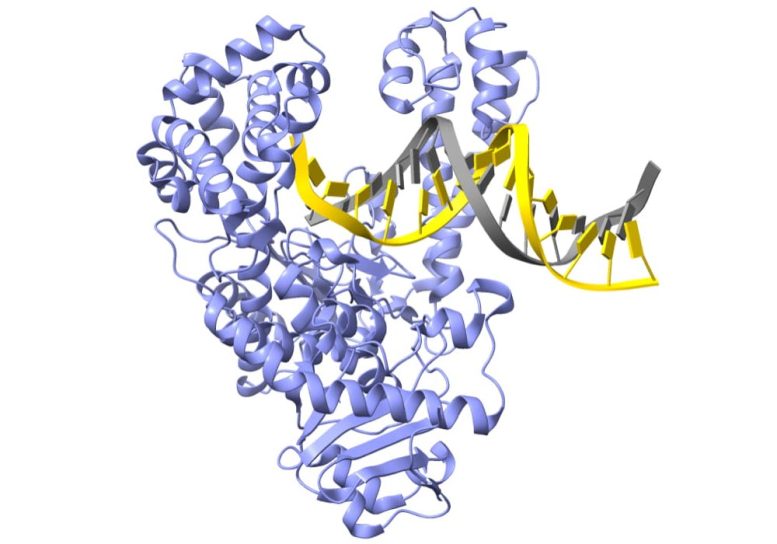
This image shows the Taq enzyme in its open configuration waiting for a new chemical base to arrive so it can try to fit it to a DNA chain. Credit: Max Strul / UCI and Lorena Beese laboratory / Duke University
The molecule the UCI-led team studied is an enzyme called Taq, a name derived from the microorganism it was first discovered in, Thermos aquaticus. The molecule the UCI-led team studied is an enzyme called Taq, a name derived from the microorganism it was first discovered in, Thermos aquaticus. Taq replicates DNA. Polymerase chain reaction, the technique with thousands of uses from forensics to PCR tests to detect COVID-19, takes advantage of Taq.
The UCI-led team found that Taq, as it helps make new copies of DNA, behaves completely unlike what scientists previously thought. Instead of behaving like a well-oiled, efficient machine continuously churning out DNA copies, the enzyme, Weiss explained, acts like an indiscriminate shopper who cruises the aisles of a store, throwing everything they see into the shopping cart.
“Instead of carefully selecting each piece to add to the DNA chain, the enzyme grabs dozens of misfits for each piece added successfully,” said Weiss. “Like a shopper checking items off a shopping list, the enzyme tests each part against the DNA sequence it’s trying to replicate.”
Il est bien connu que Taq rejette tout élément erroné qui atterrit dans son panier proverbial – ce rejet est la clé, après tout, pour réussir à dupliquer une séquence d’ADN. Ce qui est surprenant dans ces nouveaux travaux, c’est la fréquence à laquelle Taq rejette les bonnes bases. “C’est l’équivalent d’un acheteur qui prendrait une demi-douzaine de boîtes de tomates identiques, les mettrait dans son panier et les testerait toutes alors qu’une seule boîte est nécessaire.”
Le message à retenir : La Taq est beaucoup, beaucoup moins efficace pour faire son travail qu’elle ne pourrait l’être.
Cette découverte constitue un pas en avant vers la révolution des soins médicaux, a expliqué Philip Collins, professeur au département de physique et d’astronomie de l’UCI et co-auteur de la nouvelle recherche. En effet, si les scientifiques comprennent le fonctionnement de la Taq, ils pourront mieux appréhender la précision du séquençage du génome d’une personne.
“Chaque personne a un génome légèrement différent”, a déclaré Collins, “avec des mutations différentes à différents endroits. Certaines de ces mutations sont responsables de maladies, d’autres ne sont responsables de rien du tout. Pour vraiment savoir si ces différences sont importantes ou pour les soins de santé – pour prescrire correctement des médicaments – vous devez connaître ces différences avec précision.”
“Les scientifiques ne savent pas comment ces enzymes atteignent leur accuracy,” said Collins, whose lab created the nano-scale devices for studying Taq’s behavior. “How do you guarantee to a patient that you’ve accurately sequenced their DNA when it’s different from the accepted human genome? Does the patient really have a rare mutation,” asks Collins, “or did the enzyme simply make a mistake?”
“This work could be used to develop improved versions of Taq that waste less time while making copies of DNA,” Weiss said.
L’impact de ce travail ne s’arrête pas à la médecine ; chaque domaine scientifique qui dépend d’un séquençage précis de l’ADN peut bénéficier d’une meilleure compréhension du fonctionnement de Taq. Pour interpréter l’histoire de l’évolution à partir de l’ADN ancien, par exemple, les scientifiques s’appuient sur des hypothèses concernant la façon dont l’ADN évolue dans le temps, et ces hypothèses reposent sur un séquençage génétique précis.
“Nous sommes entrés dans le siècle des données génomiques”, a déclaré Collins. “Au début du siècle, nous avons démêlé le génome humain pour la toute première fois, et nous commençons à comprendre les organismes, les espèces et l’histoire de l’humanité grâce à ces nouvelles informations issues de la génomique, mais ces informations génomiques ne sont utiles que si elles sont précises.”
Référence : “Single-molecule Taq DNA polymerase dynamics” par Mackenzie W. Turvey, Kristin N. Gabriel, Wonbae Lee, Jeffrey J. Taulbee, Joshua K. Kim, Silu Chen, Calvin J. Lau, Rebecca E. Kattan, Jenifer T. Pham, Sudipta Majumdar, Davil Garcia, Gregory A. Weiss et Philip G. Collins, 11 mars 2022, Science Advances.
DOI : 10.1126/sciadv.abl3522
Les co-auteurs de cette étude sont Mackenzie Turvey, Ph.D., ancien étudiant diplômé de l’UCI en physique et astronomie, et Kristin Gabriel, Ph.D., ancien étudiant diplômé de l’UCI en biologie moléculaire et biochimie. Cette recherche a été financée par l’Institut national de recherche sur le génome humain du NIH.
![Surfside Champlain Towers South Condo Collapse et la science du béton [Video]](https://7zine.com/wp-content/uploads/2021/10/1635269596_Surfside-Champlain-Towers-South-Condo-Collapse-et-la-science-du-380x250.jpg)

